 Oggi si ritorna a qualcosa di un tantinello più complicato ma, come sempre, qualche base per i principianti verrà enucleata.
Oggi si ritorna a qualcosa di un tantinello più complicato ma, come sempre, qualche base per i principianti verrà enucleata.
Wireshark (chiamato un tempo Ethernal), come sottolineato dal titolo, è un programma che viene utilizzato per analizzare la rete e, più in specifico, il network traffic (o traffico rete). Chi ovviamente è poco pratico di computer si chiederà cosa questo significhi per cui vediamolo in breve: un network è quell’entità che collega più computer assieme; vi sono vari tipi di network come, per esempio:
- LAN, o local-area network (reta locale), che mette in comunicazione tra loro computer che si trovano nella stessa area e, generalmente, nella stessa abitazione o luogo di lavoro: spesso ci è capitato di avere a che fare con questo tipo di collegamento per esempio a scuola o lavoro, dove tutti i pc locali possono accedere ai rispettivi contenuti. Una delle reti LAN più conosciute è quella ethernet.
- WAN, o wide-area network (rete geografica) in cui i computer sono lontani ma connessi tra loro attraverso la linea telefonica o via radio: sì, esatto, Internet è effettivamente una WAN!
- CAN, o campus-area network (rete del campus), ce lo suggerisce la stessa definizione: questa è una rete universitaria o militare che collega i vari computer tra loro anche se distanti ma comunque all’interno di una specifica area geografica.
- MAN, o metropolitan-area network (rete metropolitana), anche in questo caso non è difficile indovinare che si tratti di una rete che collega vari dispositivi nell’area urbana come, per esempio, connessioni di antenne o via cavo o, ancora, la fibra ottica.
- HAN, o home-area network (rete di casa), è appunto la rete della nostra abitazione.
Ogni volta che ci connettiamo in qualche modo ad un altro dispositivo o ad internet vengono scambiati dei pacchetti di informazioni: Wireshark permette di analizzare proprio questi e di vedere, passo passo, ciò che accade all’interno della rete. Perché fare una cosa del genere, o meglio a cosa serve analizzare la nostra rete? A noi comuni mortali pressoché nulla ma se vi sono problemi come, per esempio, chiamate che cadono in continuazione mentre stiamo parlando al telefono con Tizio, si può risalire all’origine del problema (ci si riferisce qui, quindi, al troubleshooting); oppure se vogliamo ottimizzare il servizio o per potenziare la sicurezza (di norma se effettivamente lavoriamo per una ditta che si occupa di networking); oppure qualche birbante potrebbe usarlo illegalmente per inserirsi in una rete… oppure, ancora, possiamo usarlo per determinare chi è il più chiacchierone della rete in analisi, che tipo di applicazioni sono in uso, che tipo di protocolli vengono supportati dalla rete, se vi sono degli errori o dei ritardi nelle risposte di scambio pacchetti.
Il programma è open source, completamente gratuito e scaricabile al link: https://www.wireshark.org/download.html.
L’interfaccia del programma non è delle migliori ma bisogna anche calcolare che è un software sviluppato per coloro che sanno esattamente cosa stanno cercando e cosa vogliono farci: un principiante dopo aver aperto Wireshark non saprebbe nemmeno da dove cominciare e, soprattutto, dove guardare. Diamo un’occhiata quindi alla schermata che ci troviamo davanti dopo aver atteso alcuni secondi per il caricamento del programma: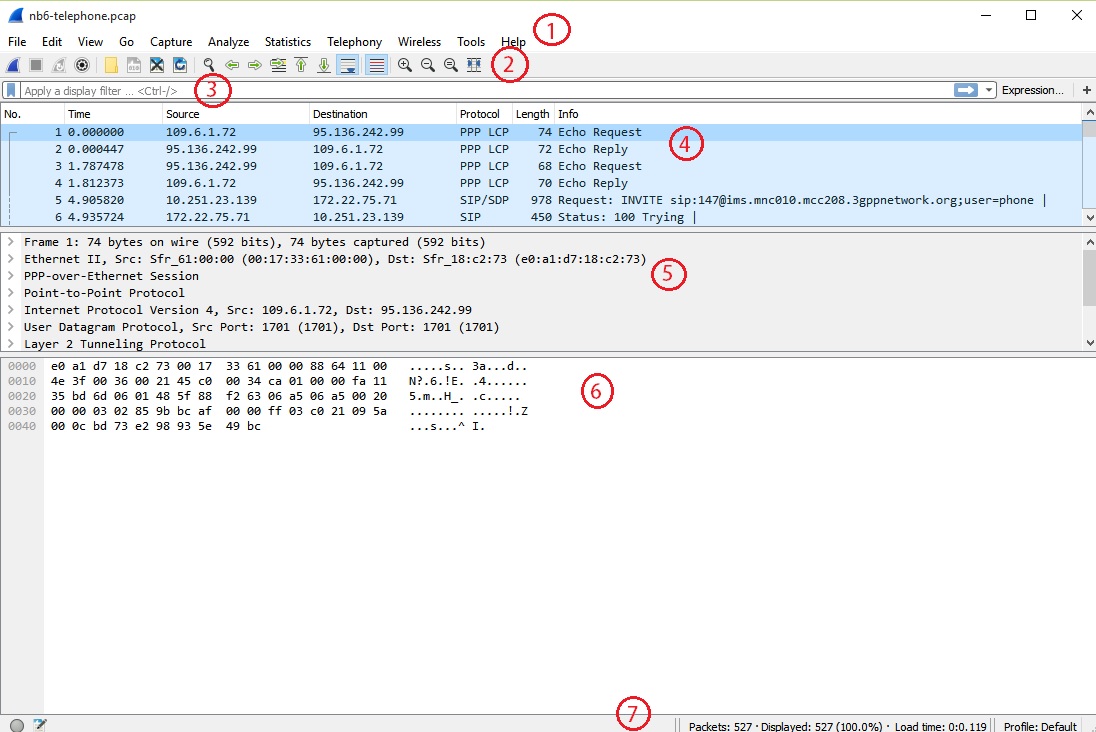
- Menu
- Toolbar
- Traffico filtrato
- Pannello lista pacchetti
- Pannello pacchetti in dettaglio
- Pannello pacchetti in bytes
- Stato
Wireshark nel processo di decodifica dei pacchetti utilizza la dissezione identificando campi e valori, a volte anche interpretandone i contenuti, relativi alla struttura della rete in analisi.
Sebbene ogni analisi del traffico in rete sia diversa vi sono alcuni passi fondamentali che, normalmente, si effettuano:
- Determinare chi sta parlando nella traccia in analisi
- Determinare che applicazioni sono attualmente in uso
- Filtrare la conversazione che ci interessa
- Tracciare il grafico dell’input/output per vedere se ci sono problemi nella trasmissione
- Aprire e controllare l’Expert per eventuali problemi nel TCP (protocollo di trasmissione pacchetti)
- Determinare il tempo di trasmissione e ricezione per identificare la possibile latenza.
Per più specifiche riguardo i punti sopraindicati consiglio di dare un’occhiata al libro Wireshark 101 – Essential skills for network analysis e Wireshark: Network Analysis entrambi di Laura Chappell.
Inoltre, la pagina wiki.wireshark ci permette anche il download di campioni da analizzare e su cui sbizzarrirsi legalmente. Ma, come sempre è sicuramente più facile se siamo alle prime armi analizzare direttamente la rete di casa nostra mentre, per esempio, eseguiamo qualche download.
Se vogliamo scaricare ed utilizzare un pacchetto dalla suddetta pagina basterà, una volta fatto il download, trascinarlo in mezzo alla finestra di Wireshark oppure andare su File > Open e cercarlo nella lista. Vediamo, però come osservare il nostro traffico in diretta:
- Una volta aperto Wireshark ed atteso alcuni secondi apparira, nella schermata principale, in basso l’immagine qui sotto riportata: come si può notare abbiamo tre possibili connessioni da selezionare: Local Area Connection, Ethernet 2 e Wi-Fi. Il computer che, in questo momento, viene analizzato sta evidentemente correndo sulla rete Ethernet 2: questo è visibile dal fatto che la linea accando non è dritta, come negli altri casi, ma frastagliata. Cliccando, quindi, due volte sopra ad Ethernet 2 potremo visualizzare il traffico in diretta.

- Noteremo allora che il traffico filtrato correrà all’impazzata mostrandoci le varie fonti, destinazioni, protocolli, etc. fino a ché non decideremo di fermarlo cliccando in alto a sinistra sul quadrato rosso Stop capturing packets (Ferma la cattura dei pacchetti).



Ora, ovviamente non posterò qui tutti i dati della mia connessione ma utilizzerò un esempio molto più semplice e noioso (ma importante sia per l’amministrazione del sistema che per la sua sicurezza) tanto per rendere l’idea di cosa si possa fare con questo programma tanto per cominciare. Ho scaricato la copia di un NTP (Network Time Protocol) a questo link: NTP_sync.pcap. Guardiamo, quindi, la prima schermata che appare una volta caricato il file su Wireshark come spiegato sopra. 
Notiamo, qui, a colpo d’occhio l’uso di due diversi protocolli, il DNS e l’NTP. Cosa sono? Allora, ogni pagina internet ha un numero IP (Internet Protocol adress) assegnato attraverso cui possiamo accedervi e, per semplificare il processo di ricerca delle stesse, spesso all’IP viene accostato anche un nome, questo nome è il DNS (Domain Name System): per esempio, www.google.it è il DNS mentre il suo numero IP è 74.125.224.72, ovviamente è più semplice ricordare il primo piuttosto che il secondo! L’NTP è, come accennato sopra, il Network Type Protocol ma cosa ci dice questo? Beh l’NTP è un protocollo utilizzato per sincronizzare gli orologi dei computer in una rete quindi, qui, in questa schermata abbiamo a che fare proprio con questo: il proprietario di questo computer da cui è stato salvato il traffico stava sincronizzando l’orologio.
Osserviamo, quindi, la prima riga relativa al traffico filtrato. Nella colonna source (fonte) troviamo il DNS client, ovvero dell’utente che produce la richiesta, 192.168.50.50 al destinatario (nella colonna Destination) 192.168.0.1.
Notiamo, inoltre, proseguendo nella sezione Info due scritte specifiche: Standard query (Domanda standard), la quale ci avverte semplicemente che l’utente sta ponendo una domanda al server mentre l’indirizzo us.pool.ntp.org specifica quale tipo di domanda viene fatta: se andiamo, infatti, a vedere di cosa si tratta scopriremo che oltre alla richiesta di sincronizzazione dell’orologio possiamo scoprire per quale fascia oraria veniva richiesta: l’indirizzo infatti punta al server degli Stati Uniti (ce lo chiosa già quel bel “us” all’interno dell’indirizzo ma qui trovate la conferma).
Nella seconda riga troviamo la risposta del server che, in un certo senso, ci dice “Sì, eccomi!” all’utente che ha fatto la richiesta. A questo seguono quindici diversi indirizzi ognuno dei quali viene contattato dal DNS client richiedendo orario. Perché così tanti indirizzi vengono utilizzati per sincronizzare un solo orario? Per un problema informatico relativo alla possibile presenza di errori chiamato il problema dei generali bizantini per cui:
Dato un numero N di processi, si richiede che al termine dell’algoritmo tutti i processi corretti impostino la variabile di decisione sullo stesso valore. Questo valore deve essere quello fornito dal processo comandante nel caso in cui questo sia corretto. I processi non corretti possono non inviare messaggi oppure inviarne con contenuto arbitrario. I messaggi non sono firmati.
Abbiamo quindi un numero N di processi che devono restituirci lo stesso valore ma dobbiamo anche tenere conto della possibilità che alcuni messaggi di risposta non siano corretti e per farlo abbiamo bisogno, appunto, di più risposte e non accontentarci della prima che ci viene fornita senza contare che non sempre possiamo avere la certezza che l’ordine dato sia stato ricevuto. Ora, questo problema dei generali bizantini si chiama così perché esso viene semplificato utilizzando proprio come esempio dei generali. Abbiamo, quindi, come scopo di raggiungere la decisione unanime di attaccare o meno all’alba (oppure, nel nostro caso di decidere se sono le 03.18.03). Si presentano allora due problemi specifici come già anticipato:
- I messaggeri inviati verso gli altri generali potrebbero essere fermati o trovati dal nemico e, quindi, i messaggi potrebbero essere persi.
- I generali potrebbero essere dei traditori e, quindi, inviare messaggi errati per confondere le acque.
Senza cadere troppo nello specifico perché non è questo il luogo, possiamo comprendere il motivo per cui non possiamo affidarci all’invio di un solo messaggero senza controllare la validità delle informazioni più volte.
Scendiamo ora alla riga tre, per esempio, che corrisponde all’invio del primo valore e clicchiamola. Prima cosa da annotare è nelle info NTP Version 3, symmetric active; questa modalità simmetrica che sia essa attiva o passiva viene utilizzata in configurazioni dove un gruppo di stratum peers bassi operano come backup mutuali tra loro in modo ridondante; ciò significa che se uno degli orologi perdesse malauguratamente i dati gli altri entreranno in gioco correggendone l’errore. Nel caso comunque della modalità simmetrica attiva il server riceve messaggi qualsiasi sia lo stato dello strato, il servizio di rete qui vuole sincronizzare ed essere sincronizzato; mentre per quanto riguarda la modalità simmetrica passiva essa si attiva il momento in cui viene contattata, come avviene nel caso in analisi, da uno strumento o da un server in modalità simmetrica attiva. Nel nostro esempio, infatti, abbiamo ben quindici richieste (da riga 3 a riga 17) dal DNS dell’utente (192.168.50.50) a cui corrisponderanno altrettante risposte, in modalità simmetrica passiva, da parte dei vari server contattati (da riga 18 a riga 32).
Lo stratum, o strato, è il livello di gerarchia nei quali vengono organizzati i diversi server NTP: se guardiamo all’immagine sottostante (presa in prestito da Wikipedia) vediamo come, effettivamente, questa gerarchia ed i server NTP funzionano. Lo strato 1 è sincronizzato direttamente con una fonte temporale esterna, ovvero degli orologi atomici (oppure GPS o orologio radiocontrollato); lo strato 2 invece riceve i dati temporali dallo strato 1 e, a sua volta, lo strato 3 da quello 2 fino ad arrivare al 4 che li riceve dallo strato 3. Gli orologi quindi si sincronizzano ricevendo dati tra loro in una sorta di scambio “ad albero”. Gli orologi atomici, nello strato che possiamo denominare 0, determinano il tempo attraverso la frequenza di risonanza di un atomo e, per questo, vengono considerati i più precisi. Vedremo, infatti poi, che scendendo nelle varie righe del nostro protocollo incontreremo anche gli altri strati.
La cosa che più ci interessa, qui, è leggere sul Pannello di lista pacchetti la parte dedicata al Network Time Protocol: per osservarne i dettagli quindi possiamo cliccare sulla freccetta alla sua sinistra.
Qui vediamo prima di tutto degli stati molto simili a quelli che troveremo fino alla riga 17 in cui vi è il Peer Clock Stratum: unspecified or invalid (0) poiché lo strumento che sta richiedendo il tempo non è conosciuto. Inoltre, notiamo anche che la richiesta di sincronizzazione dell’ora è stata fatta attorno alle 03:18 del mattino il giorno 27 settembre 2004.
Alla riga 24, per esempio, vediamo nelle info la scritta NTP Version 3, symmetric passive (come d’altronde era già presente dalla riga 18). Stiamo quindi osservando le risposte dei vari server contattati alla domanda posta. Inoltre notiamo anche che il destinatario è sempre lo stesso DNS 192.168.50.50, ovvero quell’utente che ha contattato i server chiedendo di sincronizzare l’ora sul suo computer.
Nel Pannello di lista pacchetti, al contrario dell’esempio fatto sopra e relativo alla riga 3, viene segnalato il Peer Clock Stratum: primary reference (1) ciò significa che il server si trova gerarchicamente sullo strato 1 e, quindi, è direttamente connesso all’orologio atomico. Se si fosse trovato sullo strato, per esempio, 3 vi sarebbe stato scritto secondary reference (3) e che, come spiegato sopra, sarebbe stato connesso allo strato 2 e non direttamente, quindi, all’orologio atomico.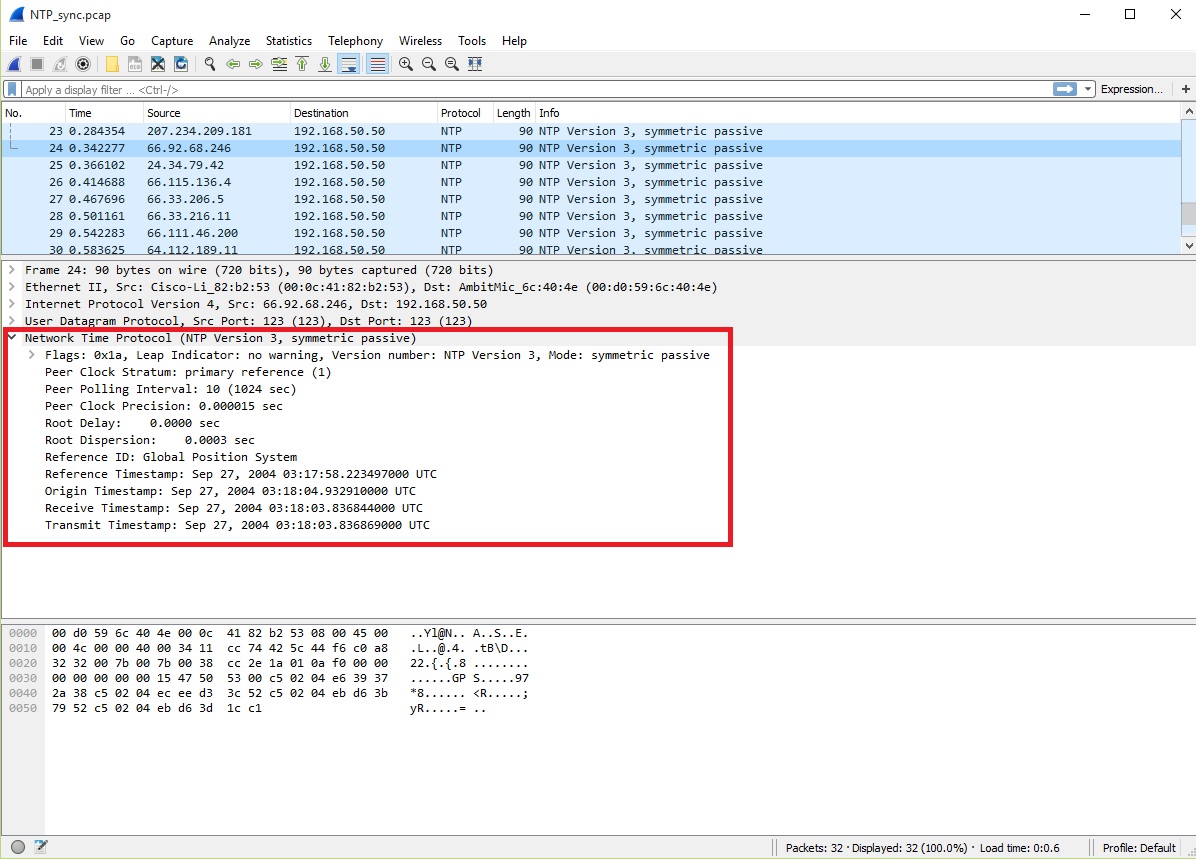
Qui vediamo vari dati interessanti:
- il peer polling interval, cioè l’intervallo di ripetizione utilizzato nel tentativo di minimizzare i possibili “rumori” nella linea, settato a 10 (1024 secondi) il che significa che il polling interval è ottimale nel caso in questione, questo perché gli intervalli di ripetizione bassi aggiornano frequentemente i parametri e sono sensibili a errori random ed il jitter (tempo di risposta del server) mentre più gli intervalli sono alti più grossi e significanti saranno le correzioni e gli errori tra i vari aggiornamenti;
- il peer clock precision che segnala la precisione dell’orologio del server settata a 0.000015 secondi;
- il root delay a 0.0000 secondi, ciò significa che il pacchetto è stato trasferito senza alcun secondo di ritardo al network;
- il root dispersion segnala il valore medio di un offset proveniente dagli ultimi otto pacchetti di dati che in questo caso è 0.0003 secondi.
- il reference ID, ovvero l’ID di referenza, qui Global Position System ma potrebbe essere anche indicato con un numero DNS come per esempio 131.107.1.10.
- ed, infine, reference timestamp (tempo di riferimento), origin timestamp (tempo di origine), receive timestamp (tempo ricevuto), transmit timestamp (tempo trasmesso) i quali, logicamente, ci rendono conto delle varie tempistiche. Notiamo, inoltre, che nelle parti in cui vi era la modalità attiva questi tempi erano completamente diversi, in alcuni casi, segnalati persino nell’anno 1970.
Come abbiamo potuto vedere restando, comunque, abbastanza in superficie già siamo riusciti ad identificare parecchie informazioni relative sia alla persona che ha inserito questo protocollo di cui abbiamo parlato fin’ora sia di come funziona la sincronizzazione degli orologi tra computer: immaginiamoci, allora, la quantità di dati che riusciremmo a recuperare, per esempio, analizzando il traffico del nostro pc o di quello di un nostro amico senza contare la possibilità di trovare eventuali errori di trasmissioni tra pacchetti o altro ancora!
Lascia un commento